
”spark hadoop“ 的搜索结果
Hadoop是Apache旗下的一个用java语言实现开源软件框架,是一个开发和运行处理大规模数据的软件平台。允许使用简单的编程模型在大量计算机集群上对大型数据集进行分布式处理。HDFS(分布式文件系统):解决海量数据...
通常情况下,Apache Spark运行速度是要比Apache Hadoop MapReduce的运行速度要快,因为Spark是在继承了MapRudece分布式计算的基础上做了内存计算的优化,从而避免了MapReduce每个阶段都要数据写入磁盘的操作,这样就...
主要用于pyshon 对spark 大数据开发使用

文件名: spark-3.4.1-bin-hadoop3.tgz 这是 Apache Spark 3.4.1 版本的二进制文件,专为与 Hadoop 3 配合使用而设计。Spark 是一种快速、通用的集群计算系统,用于大规模数据处理。这个文件包含了所有必要的组件,...
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。Storm是一个分布式的、容错的实时计算系统。两者整合,优势互补。
新的spark版本,增加了新的功能,欢迎大家下载使用!!!
apache-hive-3.1.3-bin.tar.gz apache-zookeeper-3.5.10-bin.tar.gz hadoop-3.3.3.tar.gz spark-3.2.1-bin-hadoop3.2.tgz mysql-8.0.29-1.el8.x86_64.rpm-bundle
去实习,发现工业界用的大多用这种大数据处理方式。
Hadoop Spark 类型 基础平台,包含计算、存储、调度 分布式计算工具 场景 大规模数据集上的批处理 迭代计算,交互式计算,流计算 价格 对机器要求低,便宜 对内存有要求,相对较贵 编程范式 Map+Reduce,...
Spark高清hadoop
标签: spark
图解Spark 核心技术与案例实战,很好的学习资源,希望大伙喜欢!
Spark 单机部署、集群部署 Java 访问 Spark 测试
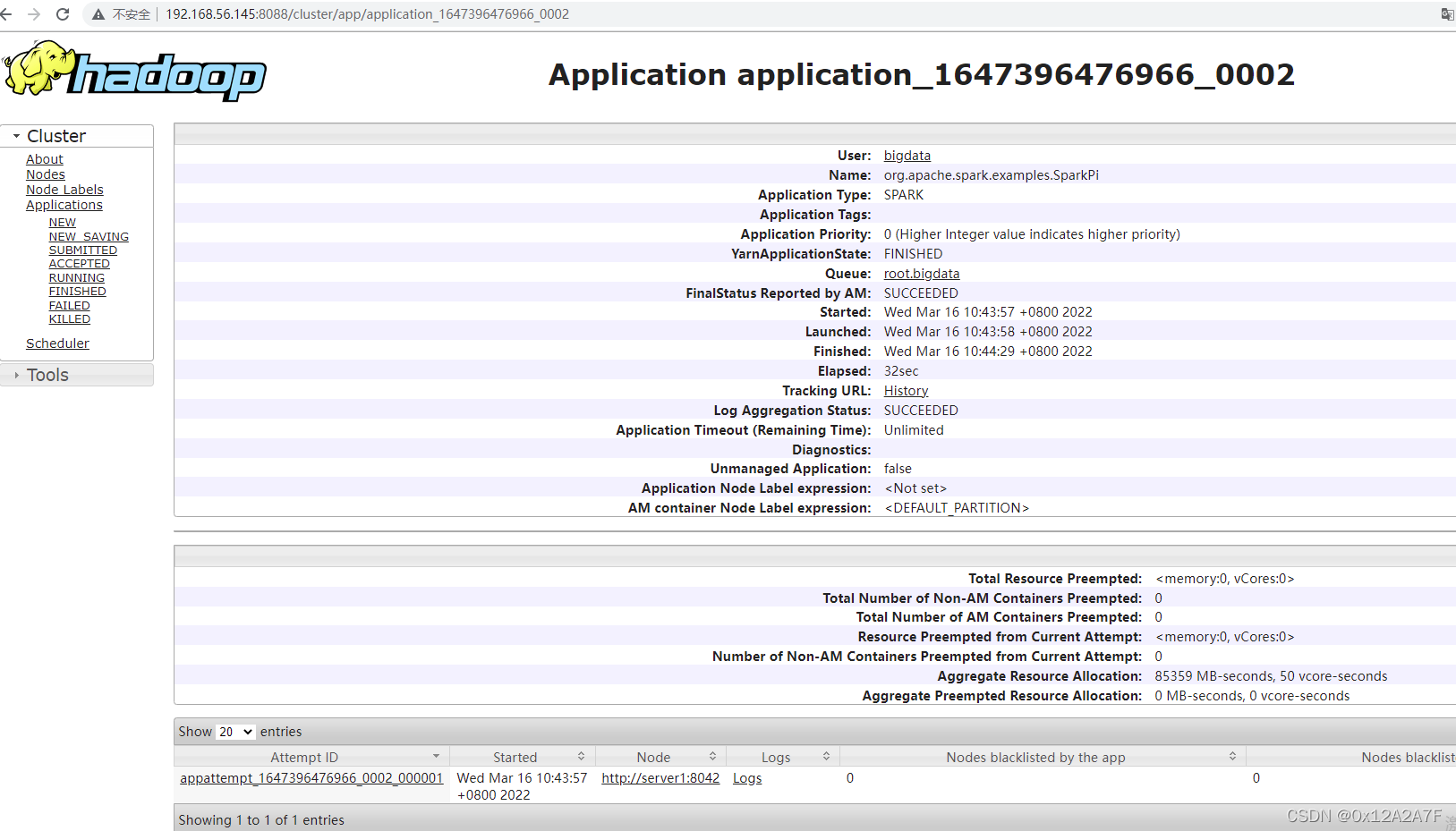
Spark streaming应用运行7天之后,自动退出,日志显示token for xxx(用户名): HDFS_DELEGATION_TOKEN [email protected], renewer=yarn, realUser=, issueDate=1581323654722, maxDate=1581928454722, sequence...

计划做一个s141~s146的分布式。 一、制作基本的docker ...安装完hadoop后,保留为centos7-ssh-hadoop 建立伪分布式,注意参考下面的(1) 配置hadoop配置文件core-site.xml、hdfs-site.xml、ma...
hadoop版本hadoop-2.7.7,spark版本spark-2.2.0-bin-hadoop2.7,搭建步骤如下: 1.配置hadoop的环境变量 F:\bigdatatool\hadoop-2.7.7\bin 修改F:\bigdatatool\hadoop-2.7.7\etc\hadoop目录下的core-site.xml、hdfs...
windows安装spark和hadoop
干翻Hadoop系列之:Hadoop、Hive、Spark的区别和联系

Hadoop和Spark都是并行计算,Hadoop一个作业称为一个Job,Job里面分为Map Task和Reduce Task阶段,每个Task都在自己的进程中运行,当Task结束时,进程也会随之结束; 好处在于进程之间是互相独立的,每个task独享...

(1)Hadoop和Spark都是并行计算,两者都是用MR模型进行计算 (2)Hadoop一个作业称为一个Job,Job里面分为Map Task和Reduce Task阶段,每个Task都在自己的进程中运行,当Task结束时,进程也会随之结束; (3)Spark...
Hadoop和Spark是复杂的框架,每个框架都实现了可以单独或一起工作的不同技术。因此,尝试使彼此平行可能会丢失更广泛的画面。 但是现实是,很多公司都在使用这两者,Hadoop用于维护和实施大数据分析,而.Spark用于...

JAVA+HADOOP+SPARK安装
二、Spark相对Hadoop的优越性 三、三大分布式计算系统 Spark,是分布式计算平台,是一个用scala语言编写的计算框架,基于内存的快速、通用、可扩展的大数据分析引擎 Hadoop,是分布式管理、存储、计算的生态系统...
推荐文章
- withRouter,非根组件获取路由参数_withrouter 只能取到路由中的一个参数-程序员宅基地
- ubuntu环境下QT5操作摄像头报错,cannot find -lpulse-mainloop-glib cannot find -lpulse cannot find -lglib-2.0_cannot find–lpulse-程序员宅基地
- 用jbpm_bpel学jwsdp的ant方式使用-程序员宅基地
- 输入数字判断星期几_html获取当前星期几-程序员宅基地
- SpringBoot整合Activiti7——实战之放假流程(会签)_activit7中会签-程序员宅基地
- 阿里云服务器收到挖矿病毒的攻击,导致基础的文件被病毒污染的问题和对应的处理解决方法-程序员宅基地
- 北京东城区空调维修办法,格力变频空调出现ph,到底是怎么回事?_格力变频空调ph代码-程序员宅基地
- vscode编辑器使用拓展插件background添加背景图片改变外观_background vscode-程序员宅基地
- android 简单打电话程序_android拨打电话的程序-程序员宅基地
- 第二届中国(泰州)国际装备高层次人才创新创业大赛_泰州市双创人才计划2022-程序员宅基地